5. Tutorial: Using MTfit with Real Data¶
The previous section has introduced many of the different options available in MTfit. This section explains the reasoning behind the choice of these parameters using a synthetic and real example.
The tutorials described here are:
- Synthetic P Polarity Inversion - Inversion of synthetic P polarity data using Monte Carlo sampling.
- Synthetic Polarity and Amplitude Ratio Inversion - Inversion of synthetic P polarity and P/SH amplitude ratio data using Monte Carlo sampling.
- Krafla P Polarity Inversion - Inversion of real P polarity data using Monte Carlo sampling, including location uncertainty.
- Krafla P Polarity Probability Inversion - Inversion of real P polarity probability data using Markov chain Monte Carlo sampling, including location uncertainty.
- Bayesian Evidence - Bayesian evidence calculation for the Monte Carlo sampled examples.
- Joint Inversion - Joint inversion of synthetic data using P polarities and relative P amplitude ratios using both Monte Carlo and Markov chain Monte Carlo sampling.
5.1. Synthetic Event¶
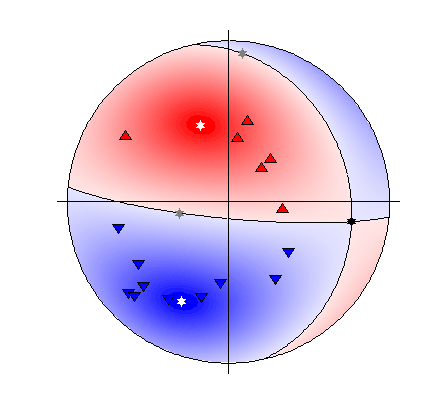
Beachball plot of the synthetic source and receiver positions for the location (Plotted using MTplot MATLAB code)
The synthetic event shown here has been generated from a double-couple source using a finite difference approach (Bernth and Chapman, 2011). Gaussian random noise was added to the data, which were manually picked for both P and S arrival times and P polarities, and then located using NonLinLoc and a simplified version of the known velocity model. The arrival time picks were used to automatically window and measure P, SH, and SV amplitudes.
5.1.1. Synthetic P Polarity Inversion¶
There are 16 P-polarity arrivals for the synthetic event, and the locations of these receivers are shown in the figure to the right. These receivers provide quite good coverage of the focal sphere, although there is not much constraint on the fault planes due to the large spacings between receivers of contrasting polarities.
>>> from example_data import synthetic_event >>> data=synthetic_event() >>> print data['PPolarity'] {'Error': matrix([[0.05], [0.05], [0.05], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [1. ], [0.01], [1. ], [1. ], [0.01], [0.05], [0.05]]), 'Measured': matrix([[-1], [-1], [ 1], [-1], [ 1], [-1], [-1], [-1], [ 1], [ 1], [-1], [-1], [-1], [ 1], [-1], [ 1]]), 'Stations': {'Azimuth': matrix([[ 55.9], [ 76.9], [277.9], [ 5.4], [224.7], [ 31.9], [ 47.9], [ 45.2], [224.6], [122.6], [328.4], [ 45.2], [309.3], [187.7], [ 16.1], [193.4]]), 'Name': ['S0517', 'S0415', 'S0347', 'S0534', 'S0244', 'S0618', 'S0650', 'S0595', 'S0271', 'S0155', 'S0529', 'S0649', 'S0450', 'S0195', 'S0588', 'S0142'], 'TakeOffAngle': matrix([[122.8], [120.8], [152.4], [138.7], [149.6], [120. ], [107.4], [117. ], [156.4], [115.3], [133.3], [109.1], [139.9], [147.2], [128.7], [137.6]])}}
examples/synthetic_event.py contains a script for the double-couple and full moment tensor inversion of the source. It can be run as:
$ python synthetic_event.py case=ppolarity
Adding a -l flag will run the inversion in a single thread.
The important part of the script is:
# print output data print(data['PPolarity']) data['UID'] += '_ppolarity' # Set inversion parameters # Use an iteration random sampling algorithm algorithm = 'iterate' # Run in parallel if set on command line parallel = parallel # uses a soft memory limit of 1Gb of RAM for estimating the sample sizes # (This is only a soft limit, so no errors are thrown if the memory usage # increases above this) phy_mem = 1 # Run in double-couple space only dc = True # Run for one hundred thousand samples max_samples = 100000 # Set to only use P Polarity data inversion_options = 'PPolarity' # Set the convert flag to convert the output to other source parameterisations convert = True # Create the inversion object with the set parameters. inversion_object = Inversion(data, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, dc=dc, max_samples=max_samples, convert=convert) # Run the forward model inversion_object.forward() # Run the full moment tensor inversion # Increase the max samples due to the larger source space to 10 million samples max_samples = 10000000 # Create the inversion object with the set parameters. inversion_object = Inversion(data, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, dc=not dc, max_samples=max_samples, convert=convert) # Run the forward model inversion_object.forward() # Equivalent to pickling the data: # >>> from example_data import synthetic_event # >>> data=synthetic_event() # >>> import cPickle # >>> cPickle.dump(data,open('synthetic_event_data.inv','wb')) # And then calling from the command line # MTfit --algorithm=iterate --pmem=1 --double-couple --max-samples=100000 \ # --inversion-options=PPolarity --convert synthetic_event_data.inv # MTfit --algorithm=iterate --pmem=1 --max-samples=10000000 \ # --inversion-options=PPolarity --convert synthetic_event_data.inv
The chosen algorithm is the iterate algorithm (see Random Monte Carlo sampling) for 100 000 samples for the double-couple case and 10 000 000 for the full moment tensor inversion.
100 000 samples in the double-couple space corresponds to approximately 50 samples in each parameter (strike, dip cosine, and rake).
While this more dense samplings are possible, this produces a good sampling of the posterior PDF quickly, especially when run in parallel.
Warning
If running this in parallel on a server, be aware that because the number of workers option number_workers is not set, as many processes as processors will be spawned, slowing down the machine for any other users.
10 000 000 samples for the full moment tensor inversion may seem like a coarse sampling, however, due to the higher noise level and the use of P polarity data only, there is much less constraint on the full moment tensor source PDF so this sampling still provides a good approximation of the results.
This script is equivalent to pickling the data:
>>> from example_data import synthetic_event
>>> data=synthetic_event()
>>> import cPickle
>>> cPickle.dump(data,open('synthetic_event_data.inv','wb'))
And then calling from the command line (Assuming parallel running: -l flag to run on a single processor):
$ MTfit --algorithm=iterate --pmem=1 --double-couple --max-samples=100000 \
--inversion-options=PPolarity --convert synthetic_event_data.inv
$ MTfit --algorithm=iterate --pmem=1 --max-samples=10000000 \
--inversion-options=PPolarity --convert synthetic_event_data.inv
These inversions should not take long to run (running on a single core of an i5 processor, the two inversions take 2 and 72 seconds respectively), although the conversions using MTfit.MTconvert can add to this time, but will reduce the time when plotting the results. The solutions are outputted as a MATLAB file for the DC and MT solutions respectively, with name synthetic_example_event_ppolarityDC.mat and synthetic_example_event_ppolarityMT.mat respectively.
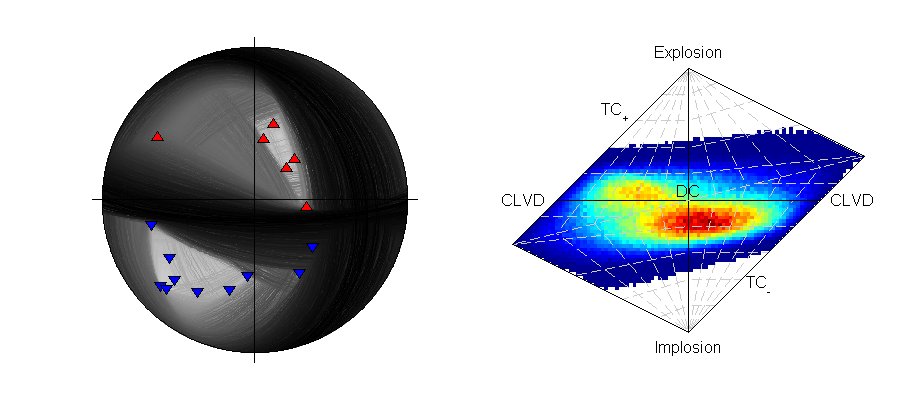
Beachball plot showing the fault plane orientations for the double-couple constrained inversion and the marginalised source-type PDF for the full moment tensor inversion of the synthetic data using polarities(Plotted using MTplot MATLAB code).
5.1.2. Synthetic Polarity and Amplitude Ratio Inversion¶
Including amplitude ratios (P/SH and P/SV) in the inversion can improve the source constraint, but, as shown in Pugh et al. 2016a, the amplitude ratio can include a systematic error that is dependent on the noise level, leading to deviations from the "True" source.
Warning
Amplitudes and amplitude ratios can show systematic deviations from the "True" value due to the noise and the method of measuring the amplitudes. Consequently, care must be taken when using amplitude ratio data in the source inversion, including tests to see if the different amplitude ratios are consistent with each other and the polarity only inversion.
These tests are ignored in this example, but can lead to very sparse solutions in the source inversion.
examples/synthetic_event.py contains a script for the double-couple and full moment tensor inversion of the source. It can be run as:
$ python synthetic_event.py case=ar
Adding a -l flag will run the inversion in a single thread.
The important part of the script is:
# print output data print(data['PPolarity']) print(data['P/SHRMSAmplitudeRatio']) print(data['P/SVRMSAmplitudeRatio']) data['UID'] += '_ar' # Set inversion parameters # Use an iteration random sampling algorithm algorithm = 'iterate' # Run in parallel if set on command line parallel = parallel # uses a soft memory limit of 1Gb of RAM for estimating the sample sizes # (This is only a soft limit, so no errors are thrown if the memory usage # increases above this) phy_mem = 1 # Run in double-couple space only dc = True # Run for one hundred thousand samples max_samples = 100000 # Set to only use P Polarity data inversion_options = ['PPolarity', 'P/SHRMSAmplitudeRatio', 'P/SVRMSAmplitudeRatio'] # Set the convert flag to convert the output to other source parameterisations convert = False # Create the inversion object with the set parameters. inversion_object = Inversion(data, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, dc=dc, max_samples=max_samples, convert=convert) # Run the forward model inversion_object.forward() # Run the full moment tensor inversion # Increase the max samples due to the larger source space to 50 million samples max_samples = 50000000 # Create the inversion object with the set parameters. inversion_object = Inversion(data, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, dc=not dc, max_samples=max_samples, convert=convert) # Run the forward model inversion_object.forward() # Equivalent to pickling the data: # >>> from example_data import synthetic_event # >>> data=synthetic_event() # >>> import cPickle # >>> cPickle.dump(data,open('synthetic_event_data.inv','wb')) # And then calling from the command line # MTfit --algorithm=iterate --pmem=1 --double-couple --max-samples=100000 \ # --inversion-options=PPolarity,P/SHRMSAmplitudeRatio,P/SVRMSAmplitudeRatio \ # --convert synthetic_event_data.inv # MTfit --algorithm=iterate --pmem=1 --max-samples=50000000 \ # --inversion-options=PPolarity,P/SHRMSAmplitudeRatio,P/SVRMSAmplitudeRatio \ # --convert synthetic_event_data.inv
The chosen algorithm is the iterate algorithm (see Random Monte Carlo sampling) for 100 000 samples for the double-couple case and 50 000 000 for the full moment tensor inversion.
100 000 samples in the double-couple space corresponds to approximately 50 samples in each parameter (strike, dip cosine, and rake).
While this more dense samplings are possible, this produces a good sampling of the posterior PDF quickly, especially when run in parallel.
Warning
If running this in parallel on a server, be aware that because the number of workers option number_workers is not set, as many processes as processors will be spawned, slowing down the machine for any other users.
50 000 000 samples are used instead of the 10 000 000 samples in the Synthetic P Polarity Inversion example because amplitude ratios provide a much stronger constraint on the source type, so more samples are required for an effective sampling of the source PDF.
This script is equivalent to pickling the data:
>>> from example_data import synthetic_event
>>> data=synthetic_event()
>>> import cPickle
>>> cPickle.dump(data,open('synthetic_event_data.inv','wb'))
And then calling from the command line (Assuming parallel running: -l flag to run on a single processor):
$ MTfit --algorithm=iterate --pmem=1 --double-couple --max-samples=100000 \
--inversion-options=PPolarity,P/SHRMSAmplitudeRatio,P/SVRMSAmplitudeRatio \
--convert synthetic_event_data.inv
$ MTfit --algorithm=iterate --pmem=1 --max-samples=10000000 \
--inversion-options=PPolarity,P/SHRMSAmplitudeRatio,P/SVRMSAmplitudeRatio \
--convert synthetic_event_data.inv
These inversions should not take long to run (running on a single core of an i5 processor, the two inversions take 20 and 436 seconds respectively), although the conversions using MTfit.MTconvert can add to this time, but will reduce the time when plotting the results. These run times are longer than for only polarity data, both because of the additional data, and the increased complexity of the ratio-pdf-label. The solutions are outputted as a MATLAB file for the DC and MT solutions respectively, with name synthetic_example_event_arDC.mat and synthetic_example_event_arMT.mat respectively.
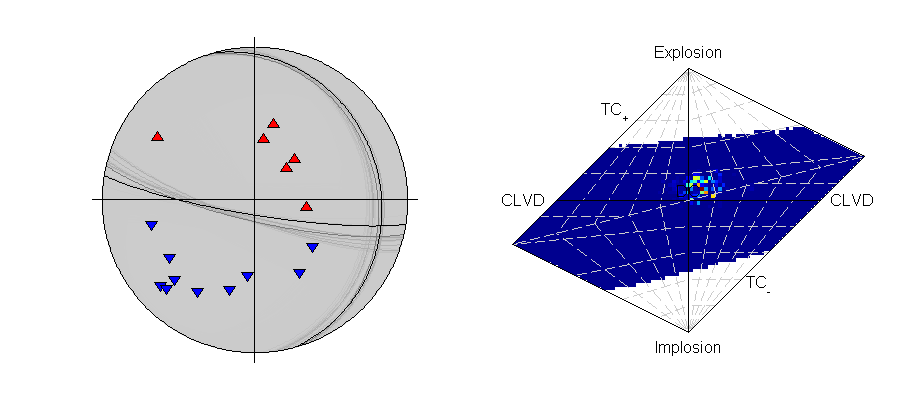
Beachball plot showing the fault plane orientations for the double-couple constrained inversion and the marginalised source-type PDF for the full moment tensor inversion of the synthetic data using polarities and amplitude ratios (Plotted using MTplot MATLAB code).
5.2. Krafla Event¶
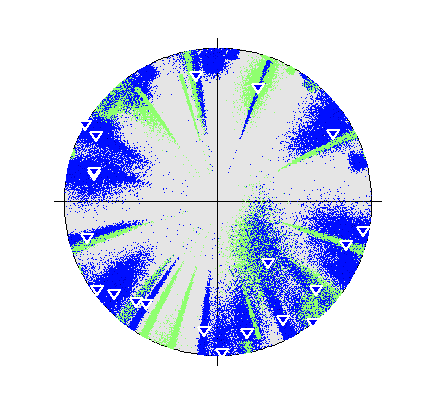
Beachball plot of the effect of the location uncertainty on the receivers (dots, darker are higher probability locations) (Plotted using MTplot MATLAB code)
A strongly non-double-couple event, with manually picked P and S arrival times and P polarities, and then located using NonLinLoc is used as an example for inversions with real data. In this case the S arrivals were hard to measure an amplitude for, so amplitude ratios are ignored. Instead, polarities and polarity probabilities (calculated using the approach described in Pugh et al. 2016a and implemented in :ref:rom autopol) are used separately to invert for the source, along with including the location data. This event is shown in Pugh et al. 2016a and investigated in more detail in Watson et al. 2015.
5.2.1. Krafla P Polarity Inversion¶
There are 21 P-polarity arrivals for the synthetic event, and the locations of these receivers are shown in the figure on the right. There is quite a large depth uncertainty, leading to a large variation in take-off angles (also shown in the figure on the right)
>>> from example_data import krafla_event >>> data=krafla_event() >>> print data['PPolarity'] {'Error': matrix([[0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01], [0.01]]), 'Measured': matrix([[-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1], [-1]]), 'Stations': {'Azimuth': matrix([[254.9], [102.5], [347.4], [178.3], [215. ], [234. ], [120.3], [350.4], [298.6], [141.8], [288.4], [186.2], [131.4], [ 48.4], [239.6], [151. ], [284. ], [ 19.6], [100.9], [319.8], [219.4]]), 'Name': ['KVO0', 'K080', 'K040', 'K200', 'REN0', 'K120', 'K100', 'K008', 'K020', 'K140', 'K060', 'K250', 'K170', 'K050', 'K090', 'K210', 'K010', 'GHA0', 'K110', 'K070', 'K220'], 'TakeOffAngle': matrix([[ 77. ], [108.8], [104.3], [ 87.4], [ 69.7], [ 86.2], [ 90.4], [ 72.1], [ 78.8], [ 90. ], [103.2], [ 73.2], [ 74.7], [101.1], [103.6], [ 76.3], [ 71.5], [ 68.1], [ 86.3], [137.5], [ 72.6]])}}
examples/krafla_event.py contains a script for the double-couple and full moment tensor inversion of the source. It can be run as:
$ python krafla_event.py case=ppolarity
Adding a -l flag will run the inversion in a single thread.
The important part of the script is:
# print output data print(data['PPolarity']) data['UID'] += '_ppolarity' # Set inversion parameters # Use an iteration random sampling algorithm algorithm = 'iterate' # Run in parallel if set on command line parallel = parallel # uses a soft memory limit of 1Gb of RAM for estimating the sample sizes # (This is only a soft limit, so no errors are thrown if the memory usage # increases above this) phy_mem = 1 # Run in double-couple space only dc = True # Run for one hundred thousand samples max_samples = 100000 # Set to only use P Polarity data inversion_options = 'PPolarity' # Set the convert flag to convert the output to other source parameterisations convert = True # Set location uncertainty file path location_pdf_file_path = 'krafla_event.scatangle' # Handle location uncertainty # Set number of location samples to use (randomly sampled from PDF) as this # reduces calculation time # (each location sample is equivalent to running an additional event) number_location_samples = 5000 # Bin Scatangle File bin_scatangle = True # Use MTfit.__core__.MTfit function MTfit(data, location_pdf_file_path=location_pdf_file_path, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, dc=dc, max_samples=max_samples, convert=convert, bin_scatangle=bin_scatangle, number_location_samples=number_location_samples) # Change max_samples for MT inversion max_samples = 1000000 # Create the inversion object with the set parameters. MTfit(data, location_pdf_file_path=location_pdf_file_path, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, dc=not dc, max_samples=max_samples, convert=convert, bin_scatangle=bin_scatangle, number_location_samples=number_location_samples) # Equivalent to pickling the data and outputting the location uncertainty: # >>> from example_data import krafla_event,krafla_location # >>> data=krafla_event() # >>> open('krafla_event.scatangle','w').write(krafla_location()) # >>> import cPickle # >>> cPickle.dump(data,open('krafla_event.inv','wb')) # And then calling from the command line # MTfit --location_pdf_file_path=krafla_event.scatangle --algorithm=iterate \ # --pmem=1 --double-couple --max-samples=100000 \ # --inversion-options=PPolarity --convert --bin-scatangle krafla_event.inv # MTfit --location_pdf_file_path=krafla_event.scatangle --algorithm=iterate \ # --pmem=1 --max-samples=10000000 --inversion-options=PPolarity --convert \ # --bin-scatangle krafla_event.inv
In this example the MTfit.__core__.MTfit() function is used instead of creating the inversion object directly. Again, the chosen algorithm is the iterate algorithm (see Random Monte Carlo sampling) for 100 000 samples for the double-couple case and 1 000 000 for the full moment tensor inversion. The location uncertainty distribution is binned (--bin_scatangle), which runs before the main inversion is carried out. This uses the MTfit.extensions.scatangle extension to both parse and bin the location PDF distribution.
Warning
If running this in parallel on a server, be aware that because the number of workers option number_workers is not set, as many processes as processors will be spawned, slowing down the machine for any other users.
This script is equivalent to pickling the data:
>>> from example_data import krafla_event
>>> data=krafla_event()
>>> import cPickle
>>> cPickle.dump(data,open('krafla_event_data.inv','wb'))
And then calling from the command line (Assuming parallel running: -l flag to run on a single processor):
$ MTfit --location_pdf_file_path=krafla_event.scatangle --algorithm=iterate \
--pmem=1 --double-couple --max-samples=100000 --inversion-options=PPolarity \
--convert --bin-scatangle krafla_event_data.inv
$ MTfit --location_pdf_file_path=krafla_event.scatangle --algorithm=iterate \
--pmem=1 --max-samples=10000000 --inversion-options=PPolarity --convert \
--bin-scatangle krafla_event_data.inv
These inversions will take longer to run than the previous examples, due to the location uncertainty (running using 8 cores, the two inversions take 4 and 11 minutes respectively), although the conversions using MTfit.MTconvert can add to this time, but will reduce the time when plotting the results. The solutions are outputted as a MATLAB file for the DC and MT solutions respectively, with name krafla_event_ppolarityDC.mat and krafla_event_ppolarityMT.mat respectively.
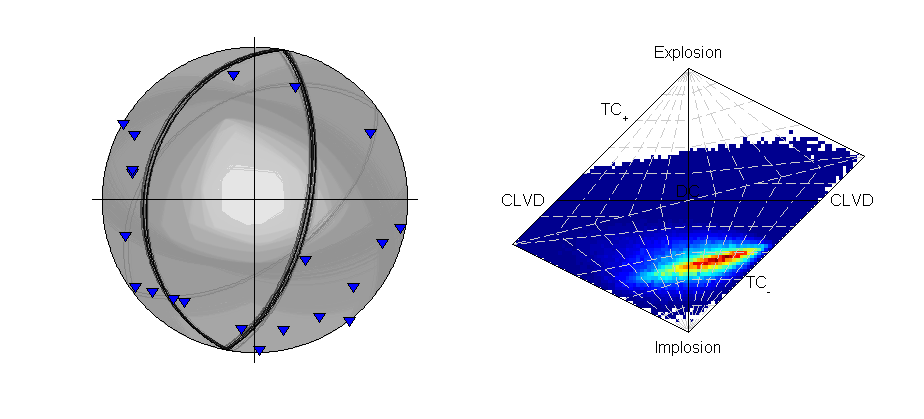
Beachball plot showing the fault plane orientations for the double-couple constrained inversion and the marginalised source-type PDF for the full moment tensor inversion of the krafla data using polarities(Plotted using MTplot MATLAB code).
5.2.2. Krafla P Polarity Probability Inversion¶
There are 21 P-polarity arrivals for the synthetic event, but more observations, and a better understanding of the uncertainties on the polarities can be obtained using the automated Bayesian polarity probabilities generated using the approach described in Pugh et al., 2016b, Pugh, 2016a. Nevertheless, much of this example is the same as the Krafla P Polarity Inversion example.
examples/krafla_event.py contains a script for the double-couple and full moment tensor inversion of the source. It can be run as:
$ python krafla_event.py case=ppolarityprob
Adding a -l flag will run the inversion in a single thread.
The important part of the script is:
# print output data print(data['PPolarityProb']) data['UID'] += '_ppolarityprob' # Set inversion parameters # Use an mcmc sampling algorithm algorithm = 'mcmc' # Set parallel to false as running McMC parallel = False # uses a soft memory limit of 0.5Gb of RAM for estimating the sample sizes # (This is only a soft limit, so no errors are thrown if the memory usage # increases above this) phy_mem = 0.5 # Run both inversions dc_mt = True # Run for one hundred thousand samples chain_length = 100000 # Set to only use P Polarity data inversion_options = 'PPolarityProb' # Set the convert flag to convert the output to other source parameterisations convert = True # Set location uncertainty file path location_pdf_file_path = 'krafla_event.scatangle' # Handle location uncertainty # Set number of location samples to use (randomly sampled from PDF) as this # reduces calculation time # (each location sample is equivalent to running an additional event) number_location_samples = 5000 # Bin Scatangle File bin_scatangle = True # Use MTfit.__core__.MTfit function MTfit(data, location_pdf_file_path=location_pdf_file_path, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, chain_length=chain_length, convert=convert, bin_scatangle=bin_scatangle, dc_mt=dc_mt, number_location_samples=number_location_samples) # Trans-Dimensional inversion data['UID'] += '_transd' # Use a transdmcmc sampling algorithm algorithm = 'transdmcmc' # Use MTfit.__core__.MTfit function MTfit(data, location_pdf_file_path=location_pdf_file_path, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, chain_length=chain_length, convert=convert, bin_scatangle=bin_scatangle, number_location_samples=number_location_samples) # Equivalent to pickling the data and outputting the location uncertainty: # >>> from example_data import krafla_event,krafla_location # >>> data=krafla_event() # >>> open('krafla_event.scatangle','w').write(krafla_location()) # >>> import cPickle # >>> cPickle.dump(data,open('krafla_event_data.inv','wb')) # And then calling from the command line # MTfit --location_pdf_file_path=krafla_event.scatangle --algorithm=mcmc -b \ # --pmem=1 --double-couple --max-samples=100000 \ # --inversion-options=PPolarityProb --convert --bin-scatangle \ # krafla_event.inv # MTfit --location_pdf_file_path=krafla_event.scatangle --algorithm=transdmcmc \ # --pmem=1 --max-samples=100000 --inversion-options=PPolarityProb \ # --convert --bin-scatangle krafla_event.inv
In this example the MTfit.__core__.MTfit() function is used instead of creating the inversion object directly. The chosen algorithm is the mcmc algorithm (see Markov chain Monte Carlo sampling) for a chain length of 100 000 samples for both the double-couple case and the full moment tensor inversion. Additionally a trans-dimensional McMC approach is run, allowing comparison between the two.
The location uncertainty distribution is binned (--bin_scatangle), which runs before the main inversion is carried out. This uses the MTfit.extensions.scatangle extension to both parse and bin the location PDF distribution.
Warning
If running this in parallel on a server, be aware that because the number of workers option number_workers is not set, as many processes as processors will be spawned, slowing down the machine for any other users.
This script is equivalent to pickling the data:
>>> from example_data import krafla_event
>>> data=krafla_event()
>>> import cPickle
>>> cPickle.dump(data,open('krafla_event_data.inv','wb'))
And then calling from the command line:
$ MTfit --location_pdf_file_path=krafla_event.scatangle -l --algorithm=mcmc -b \
--pmem=1 --double-couple --max-samples=100000 --inversion-options=PPolarityProb \
--convert --bin-scatangle krafla_event_data.inv
$ MTfit --location_pdf_file_path=krafla_event.scatangle -l --algorithm=transdmcmc \
--pmem=1 --max-samples=100000 --inversion-options=PPolarityProb --convert \
--bin-scatangle krafla_event_data.inv
These inversions will take longer to run than the previous examples, both due to the location uncertainty, the McMC algorithms, and the non-parallel running (running on a single process on an i5 processor, the inversions take 7 hours), although the conversions using MTfit.MTconvert can add to this time, but will reduce the time when plotting the results. The solutions are outputted as a MATLAB file for the DC and MT solutions respectively, with name krafla_event_ppolarityDC.mat and krafla_event_ppolarityMT.mat respectively.
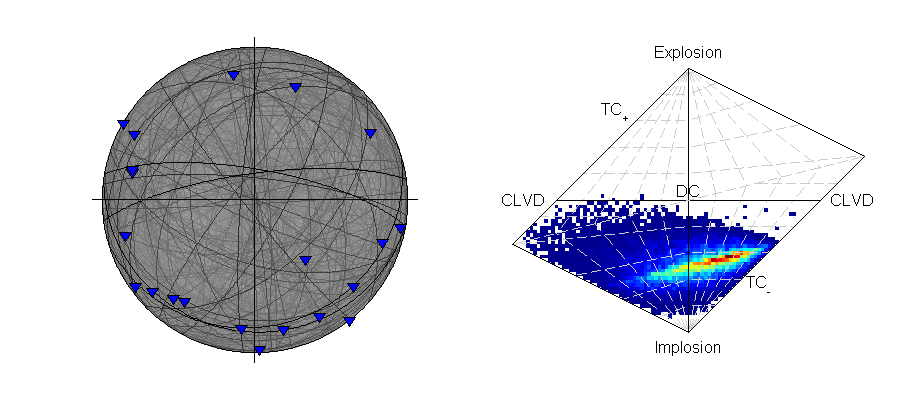
Beachball plot showing the fault plane orientations for the double-couple constrained inversion and the marginalised source-type PDF for the full moment tensor inversion of the krafla data using polarity probabilities (Plotted using MTplot MATLAB code).
The transdmcmc algorithm option produces similar results to the normal McMC example, and both results are consistent with the random sampling approach for polarity data (Krafla P Polarity). The chain-lengths may be on the long side, and it is possible that shorter chains would produce satisfactory sampling of the solution PDF.
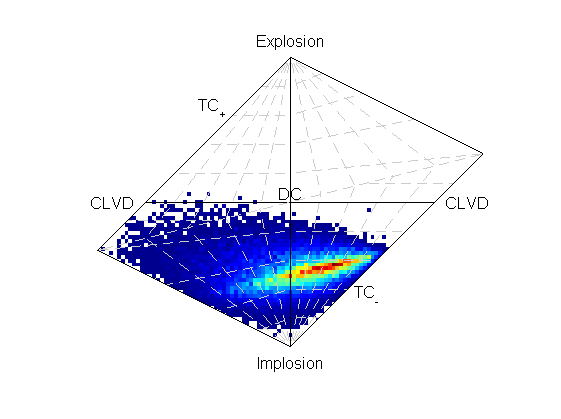
The marginalised source-type PDF for the full moment tensor inversion of the krafla data using polarity probabilities and the reversible jump (trans-dimensional) McMC approach (Plotted using MTplot MATLAB code).
5.3. Bayesian Evidence¶
The Bayesian evidence estimates the evidence for the model given the posterior PDF and the parameter priors. It accounts for the model dimensions, and can penalise the higher dimensional model by the parameter priors. The Bayesian evidence is:
Since MTfit produces random samples of the source PDF, so the Bayesian evidence is calculated as a sum over the samples:
but care must be taken with the choice of the prior parameterisation. This must correspond to the same parameterisation in which the Monte Carlo samples were drawn, either directly or by correcting both the prior distribution and the \(\delta x\) values. A Monte Carlo approach can be affected by small sample sizes in the integration, which is sometimes the case when the source PDF is dominated by a few very large probability samples.
MTfit produces a Bayesian evidence estimate for a constrained inversion. These can be combined for the DC and MT models, with \(\mathcal{B}\) corresponding to a Bayesian evidence estimate:
For the examples shown above, the model probability estimates from the Bayesian evidence are:
| Example | \(p_\mathrm{DC}\) | \(p_\mathrm{MT}\) |
|---|---|---|
| Synthetic Polarities | \(0.64\) | \(0.36\) |
| Synthetic Polarity and Amplitude Ratios | \(0.82\) | \(0.18\) |
| Krafla P Polarity | \(0.0008\) | \(0.9992\) |
These can be calculated using the MTfit.probability.model_probabilities() function, which takes the logarithm of the Bayesian evidence for each model type as an argument:
-
MTfit.probability.model_probabilities(*args)[source]¶ Calculate the model probabilities for a discrete set of models using the ln_bayesian_evidences, provided as args.
e.g. to compare between DC and MT:
pDC,pMT=model_probabilities(dc_ln_bayesian_evidence,mt_ln_bayesian_evidence)- Args
- floats - ln_bayesian_evidence for each model type
- Returns
- tuple: Tuple of the normalised model probabilities for the corresponding
- ln_bayesian_evidence inputs
The normal McMC approach cannot be used to estimate the model probabilities, however the trans-dimensional example is consistent with the Krafla P Polarity model probabilities as that produces an estimate \(p_\mathrm{DC}=0\).
MTfit also calculates the Kullback-Liebler divergence of the resultant PDF from the sampling prior, which is a measure of how much difference there is between the resultant PDF and the prior information. This is outputted during the inversion approach (when using Monte Carlo random sampling), and saved to the output file.
5.4. Joint Inversion¶
MTfit can also carry out joint invesions and include relative amplitude data (Pugh et al., 2015t). This examples uses data from two co-located synthetic events with overlapping receivers.
examples/relative_event.py contains a script for the double-couple and full moment tensor inversion of the source. It can be run as:
$ python relative_event.py
Adding a -l flag will run the inversion in a single thread.
The important part of the script is:
# Set inversion parameters # Use an iteration random sampling algorithm algorithm = 'iterate' # Run in parallel if set on command line parallel = parallel # uses a soft memory limit of 1Gb of RAM for estimating the sample sizes # (This is only a soft limit, so no errors are thrown if the memory usage # increases above this) phy_mem = 1 # Run in double-couple space only dc = True # Run for 10 million samples - quite coarse for relative inversion of two events max_samples = 10000000 # Set to only use P Polarity data inversion_options = ['PPolarity', 'PAmplitude'] # Set the convert flag to convert the output to other source parameterisations convert = True # Create the inversion object with the set parameters. inversion_object = Inversion(data, algorithm=algorithm, parallel=parallel, inversion_options=inversion_options, phy_mem=phy_mem, dc=dc, max_samples=max_samples, convert=convert, multiple_events=True, relative_amplitude=True) # Run the forward model inversion_object.forward() # Run the full moment tensor inversion # Use mcmc algorithm for full mt space as random sampling can require a # prohibitive number of samples algorithm = 'mcmc' # Set McMC parameters burn_length = 30000 chain_length = 100000 min_acceptance_rate = 0.1 max_acceptance_rate = 0.3 # Create the inversion object with the set parameters. inversion_object = Inversion(data, algorithm=algorithm, parallel=False, inversion_options=inversion_options, phy_mem=phy_mem, dc=not dc, chain_length=chain_length, max_acceptance_rate=max_acceptance_rate, min_acceptance_rate=min_acceptance_rate, burn_length=burn_length, convert=convert, multiple_events=True, relative_amplitude=True) # Run the forward model inversion_object.forward() # Equivalent to pickling the data: # >>> from example_data import relative_event # >>> data=relative_event() # >>> import cPickle # >>> cPickle.dump(data,open('relative_event_data.inv','wb')) # And then calling from the command line # MTfit --algorithm=iterate --pmem=1 --double-couple --max-samples=10000000 \ # --inversion-options=PPolarity,PAmplitude --convert --relative \ # --multiple-events relative_event_data.inv # MTfit --algorithm=mcmc --pmem=1 --chain-length=100000 \ # --burn_in=30000 --min_acceptance_rate=0.1 \ # --max_acceptance_rate=0.3 --inversion-options=PPolarity,PAmplitude \ # --convert --relative --multiple-events relative_event_data.inv
In this example the MTfit.inversion.Inversion class is created directly. The chosen algorithm for the double-couple inversion is the iterate algorithm (see Random Monte Carlo sampling) for 10 000 000 samples for the double-couple case. A large sample size is required when running the joint inversion because if the probabilities of obtaining a non-zero probability sample for both events is less than or equal to the product of the probabilities of obtaining a non-zero probability sample for the events individually, i.e if the fraction of non-zero probability samples for event 1 is \(f_1\) and the fraction for event 2 is \(f_2\), then the fraction for the joint samping \(f_j \leq f_1.f_2\). Consequently it soon becomes infeasible to run the monte-carlo sampling algorithm for the full moment tensor case.
The full moment tensor inversion uses the mcmc algorithm to reduce the dependence of the result on the sample size. The burn in length is set to 30 000 and the chain length to 100 000, while the targeted acceptance rate window is reduced from the normal McMC selection (0.3 - 0.5), instead targetting between 0.1 and 0.3.
Warning
If running this in parallel on a server, be aware that because the number of workers option number_workers is not set, as many processes as processors will be spawned, slowing down the machine for any other users.
This script is equivalent to pickling the data:
>>> from example_data import relative_event
>>> data=relative_event()
>>> import cPickle
>>> cPickle.dump(data,open('relative_event_data.inv','wb'))
And then calling from the command line:
$ MTfit --algorithm=iterate --pmem=1 --double-couple --max-samples=10000000 \
--inversion-options=PPolarity,PAmplitude --convert --relative \
--multiple-events relative_event_data.inv
$ MTfit --algorithm=mcmc --pmem=1 --chain-length=100000 \
--burn_in=30000 --min_acceptance_rate=0.1 \
--max_acceptance_rate=0.3 --inversion-options=PPolarity,PAmplitude \
--convert --relative --multiple-events relative_event_data.inv
These inversions will take longer to run than the previous examples, due to the increased sample size required for the joint PDF. The solutions are outputted as a MATLAB file for the DC and MT solutions respectively, with name MTfitOutput_joint_inversionDC.mat and MTfitOutput_joint_inversionMT.mat respectively.
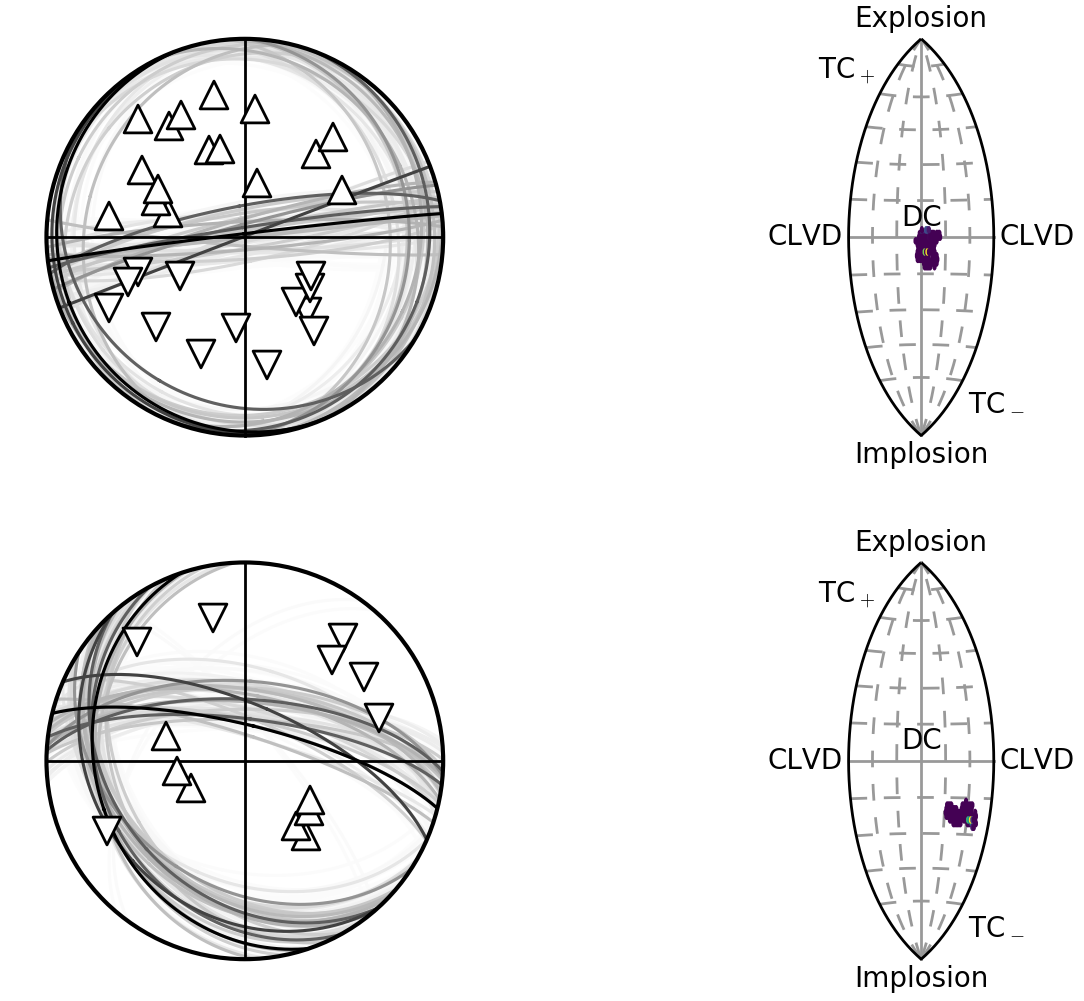
Beachball plot showing the fault plane orientations for the double-couple constrained inversion and the marginalised source-type PDF for the full moment tensor inversion for two events, inverted using P polarities and relative P amplitude ratios.
These have improved the constraint compared to the joint inversion without relative amplitudes:
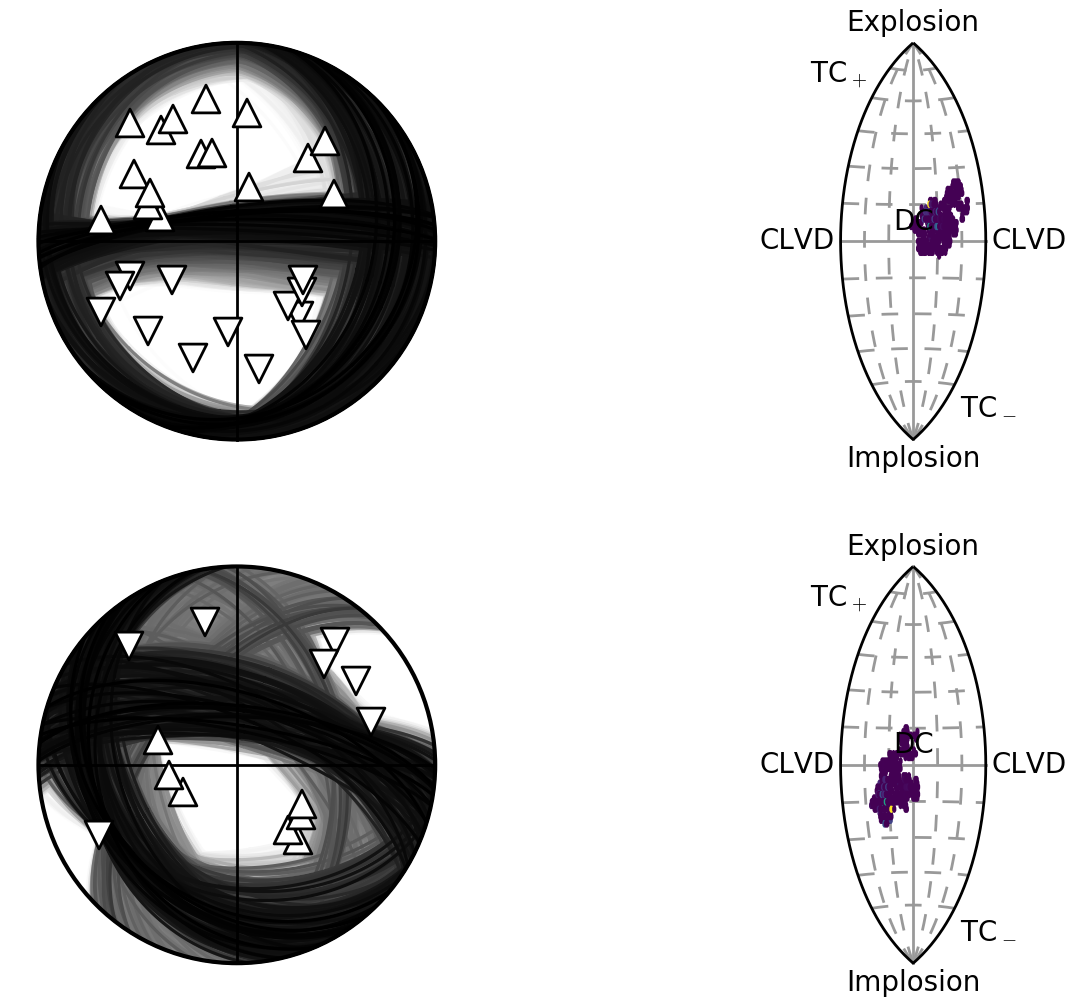
Beachball plot showing the fault plane orientations for the double-couple constrained inversion and the marginalised source-type PDF for the full moment tensor inversion for two events, inverted using P polarities.
Althought the constraint has improved, the relative amplitudes have changed the full moment tensor solution for the second event, possibly due to errors in the P-amplitude estimation (Pugh et al., 2016a).